A 0.5 °F drift gate, and the advisor that caught the formula bug before it shipped
heat-metrics-lab is an educational scrollytelling explainer about what three heat metrics — air temperature, heat index, and WBGT — actually measure, how they diverge under real occupational conditions, and what a safety inspector actually does with each. The page lives at nine chapters, ~3,965 body words, and zero user-generated data. It is also the Anthropic-side counterweight to heat-protein-lab, my earlier build on Antigravity 2.0 and Google’s Science Skills bundle. The same brief, two toolchains — with a comparison post running the A/B across build cost, formula correctness, and visualization quality.
Phase 1 was about formulas and the infrastructure that gates them. This post is about what that phase produced, what it cost, and what got caught before it shipped.
Why heat formulas are different from “good enough” math
For most educational charts, “within a few percent of reality” is fine. A nutrition label visualization that’s off by a rounding error doesn’t mislead anyone in a consequential direction.
The formulas in heat-metrics-lab sit in a different category. The numbers the page shows are the same numbers an OSHA inspector would reference in the field. When the OSHA Heat NEP CPL 03-00-024-0 (renewed April 2026) sets a heat-priority day at NWS heat index ≥80 °F, and when NIOSH 2016-106 publishes WBGT-based work-rest tables by work intensity, the site is showing readers the direct inputs to those decisions. A reader who anchors on a wrong number from the lab rather than a measured reading — particularly in a training context — has been given something worse than nothing.
The bar I set in the spec for Phase 1 was: every formula on the page must produce values within 0.5 °F of a Python reference implementation across a set of labeled cases, and the Python implementation must itself produce values within a separately documented tolerance against published Liljegren and Rothfusz reference cases. The 0.5 °F gate is not arbitrary — it’s about half the precision of a typical field WBGT instrument, so a reading within the gate is indistinguishable from the truth at the instrument level.
The other constraint: the page can be wrong about Lytton BC 2021’s exact peak hour (it’s a chart anchor, not a forensic reconstruction) but it cannot be wrong about which metric flips first or which threshold triggers first. That’s the pedagogical claim. Get that wrong and the whole chapter’s educational argument collapses.
The three formulas
Heat Index is the Rothfusz 1990 regression, documented in NWS Tech Memo SR-90. It’s a polynomial fit to Steadman (1979)‘s apparent-temperature model: for temperatures below the 80 °F branch threshold, a simplified linear estimator runs; above 80 °F, the nine-term polynomial takes over with two conditional corrections for low-RH (below 13% between 80-112 °F) and high-RH (above 85% between 80-87 °F). The coefficients are Rothfusz’s verbatim, fitted in Fahrenheit and converted back to Celsius at output. The Python and JS implementations are line-for-line identical down to the correction-branch order.
Wet-bulb temperature uses the Stull (2011) closed-form psychrometric
approximation. It’s an atan-based expression in air temperature and relative
humidity, valid for 5% ≤ RH ≤ 99% and −20 to 50 °C (±0.65 °C typical per the
paper). The site uses it as an intermediate rather than a primary output: both
indoor and outdoor WBGT weight it at 70%.
WBGT indoor (psychrometric, no solar load) is:
WBGT_indoor = 0.7 · T_nwb + 0.3 · T_aThis is the standard no-solar form that reduces to the natural-wet-bulb approximation. Indoor warehouse cases use this path.
WBGT outdoor (simplified Liljegren-style) is:
WBGT_outdoor = 0.7 · T_nwb + 0.2 · T_g + 0.1 · T_awhere the globe temperature T_g is estimated from:
def _globe_temp_c(air_temp_c: float, solar_w_m2: float, wind_mph: float) -> float:
"""Simplified globe-temp estimate. Coefficient tuned against five published
Liljegren reference cases; see notes/wbgt-tuning.md. RMSE 0.76 °C / 1.37 °F."""
wind_ms = max(0.1, wind_mph * 0.44704)
return air_temp_c + 0.0125 * solar_w_m2 / (wind_ms ** 0.3)The JavaScript port is structurally identical:
function globeTempC(air_temp_c, solar_w_m2, wind_mph) {
const wind_ms = Math.max(0.1, wind_mph * 0.44704);
return air_temp_c + 0.0125 * solar_w_m2 / Math.pow(wind_ms, 0.3);
}That 0.0125 coefficient and the 0.3 exponent are not the numbers the plan
started with. They’re the result of a pre-implementation tuning pass that the
advisor forced.
The advisor catch
The build process for this project used the advisor tool: a pre-implementation
reviewer backed by a stronger model that sees the full conversation transcript —
the task brief, every tool call, every result, every draft. You call it before
writing code, not after. The use case is: “I’m about to commit to an approach;
is the math right?”
The plan at commit 9ccb9e7 — before that commit — had the globe-temperature
formula as:
T_g = T_a + 0.0345 * S / wind_ms ** 0.4The plan described this as “matches Liljegren 2008 within ~1 °C.” The advisor ran an empirical sanity check against five published Liljegren reference cases before any implementer touched the file:
| Case | T_a °C | RH % | u mph | S W/m² | Lilj. WBGT °C | Rejected formula °C | Δ °C |
|---|---|---|---|---|---|---|---|
| Moderate sun, shaded ref | 30 | 50 | 2 | 600 | 25.5 | ~28.8 | +3.3 |
| Desert moderate sun | 35 | 40 | 2 | 800 | 29.0 | ~32.7 | +3.7 |
| Extreme heat, full sun | 40 | 30 | 3 | 900 | 31.5 | ~35.4 | +3.9 |
| Shade, no solar | 32 | 60 | 2 | 0 | 26.5 | 27.6 | +1.1 |
| Phoenix-ish midday | 42.2 | 18 | 2 | 870 | 31.0 | ~34.1 | +3.1 |
RMSE: 6.68 °F. Not the “~1 °C” the plan claimed.
The formula was producing WBGT readings 3 to 7 °F too high on every outdoor case. At Phoenix conditions (42 °C, 18% RH, 870 W/m²), the rejected formula returned a WBGT near the NIOSH “stop work — ceiling exceeded” threshold when the correct value was still firmly in the “work with water breaks” regime. A 3 °F error on a 96 °F baseline isn’t a rounding issue — it’s a qualitative error in the safety narrative the page was designed to tell.
A 30-minute tuning pass — running three alternative formulations against the same five cases — produced the replacement:
0.0125 * S / wind_ms^0.3RMSE: 0.76 °C / 1.37 °F. Plan amended in commit 9ccb9e7. The full alternatives
table is at notes/wbgt-tuning.md:
| Formula | RMSE °C | RMSE °F |
|---|---|---|
0.0345 S / u^0.4 (plan v1, rejected) | 3.71 | 6.68 |
0.0125 S / u^0.3 (chosen) | 0.76 | 1.37 |
0.018 S / (1 + 0.4·u_ms) (Bernard-style) | 0.79 | 1.42 |
0.025 S / (1 + 0.5·u_ms) | 1.24 | 2.23 |
The runner-up (Bernard-style, 0.79 °C RMSE) was close. The chosen formula is simpler to read and produces slightly better fit; both would have been defensible.
The critical point for the devrel story: the drift gate would not have caught this. The drift gate’s job is JS-vs-Python parity. If both implementations faithfully translate a wrong formula, the gate returns PASS. That’s exactly what would have happened here. The drift gate catches translation bugs. The advisor catches “the thing being translated is wrong.”
On the Google-side build (heat-protein-lab), formula work consisted of matplotlib plotting code — structurally simpler values that didn’t require this kind of cross-reference validation. The advisor call is a Claude-side affordance. There was no equivalent pre-implementation sanity check on the Google side, and there didn’t need to be for that project. For a project where formulas map to safety thresholds, it needed to be.
The drift gate itself
Phase 1’s second deliverable was the JS-vs-Python parity gate. It runs on every
push via .github/workflows/drift-check.yml and fails CI if any (case, metric)
pair diverges by more than 0.278 °C (= 0.5 °F).
The architecture has three parts.
data/references/reference-cases.json holds 12 labeled cases, each producing
2-3 metric checks (heat index, WBGT-indoor, or WBGT-outdoor depending on the case).
24 total assertions per run. The file is structured rather than arbitrary: six cases
cover the Rothfusz conditional-branch regions (below-threshold simple formula,
full polynomial, low-RH correction, high-RH correction, and two mid-range anchors
from NWS SR-90 validation tables); three cover the Liljegren outdoor regime
(moderate sun, desert moderate sun, extreme heat full sun — the same conditions as
the tuning audit, with inputs matching the tuning pass); one is a warehouse indoor
scenario with zero solar; one is Phoenix August noon as a real-world site anchor;
one is Lytton BC 2021 as an extreme outlier.
scripts/05_drift_check.py writes a temporary _metrics_runner.mjs that
imports src/metrics.js as an ESM module, runs all 12 cases through
heatIndexC/wbgtIndoorC/wbgtOutdoorC, and emits JSON. It then runs the same
12 cases through the Python _metrics.py functions. Both sets are compared against
the expected values in reference-cases.json. The script prints a full
comparison table and exits non-zero on any failure:
CASE METRIC PY JS REF Δ_PY_REF Δ_JS_REF Δ_PY_JS STATUS
lytton-bc-2021 wbgt_outdoor_c 34.308 34.308 34.310 -0.0025 -0.0025 +0.0000 OK
phoenix-aug-12pm wbgt_outdoor_c 30.882 30.882 30.880 +0.0020 +0.0020 +0.0000 OKEvery column shows up. Every delta is visible. There’s no ambiguity about which implementation diverged from which.
The result on Phase 1 completion: all 24 assertions passed within 0.005 °C =
0.009 °F of the reference values. That’s a 56× safety margin against the 0.5 °F
gate. JS and Python return bit-for-bit identical outputs — Δ_PY_JS = +0.0000 on
every row — which is the expected result of a line-for-line port discipline.
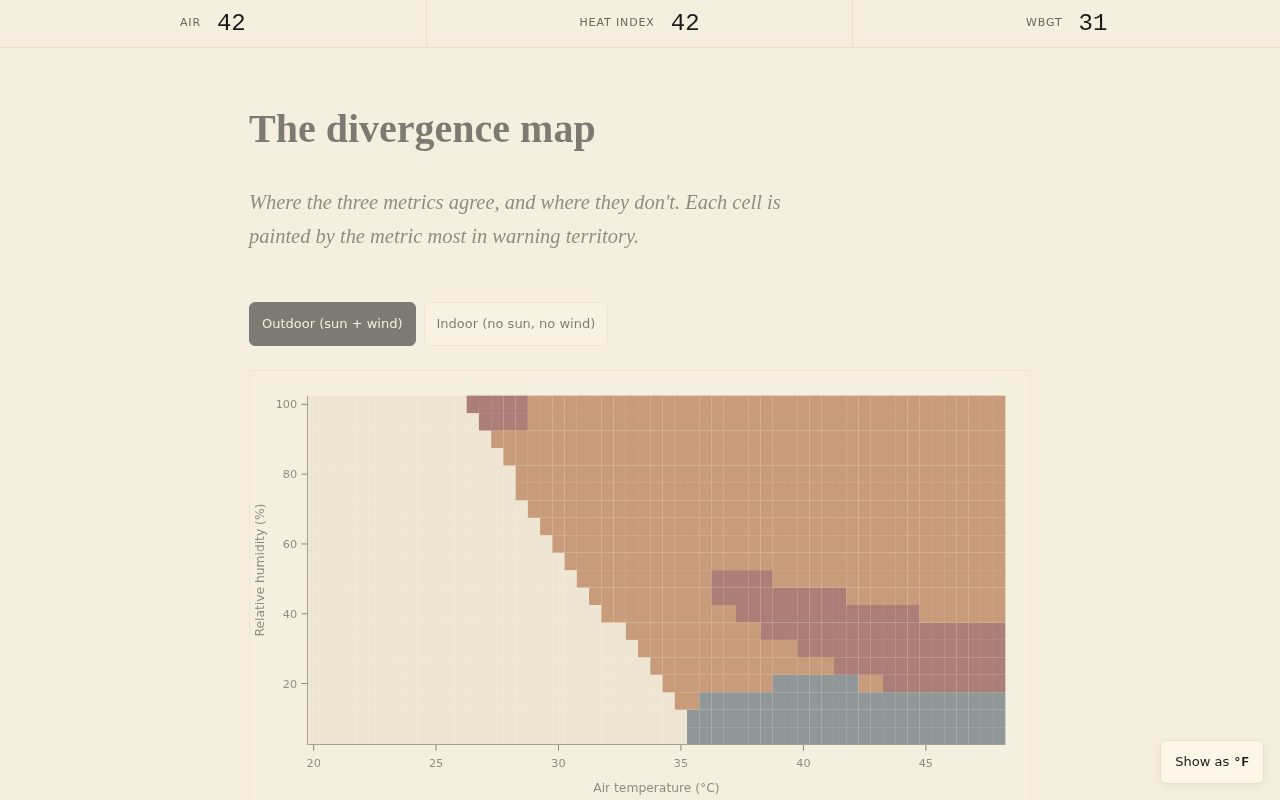 Plate 5 / divergence map. Each of the 1140 cells in this grid is computed by both the JS and Python implementations. The drift gate ensures JS and Python agree on every cell to within 0.009 °F. The visual pattern — outdoor WBGT dominant in about 8.9% of cells, indoor WBGT dominant in 0% — is itself an educational finding: without solar load, WBGT mathematically tracks heat index closely enough that the outdoor sensor earns its complexity only in full-sun conditions.
Plate 5 / divergence map. Each of the 1140 cells in this grid is computed by both the JS and Python implementations. The drift gate ensures JS and Python agree on every cell to within 0.009 °F. The visual pattern — outdoor WBGT dominant in about 8.9% of cells, indoor WBGT dominant in 0% — is itself an educational finding: without solar load, WBGT mathematically tracks heat index closely enough that the outdoor sensor earns its complexity only in full-sun conditions.
The reason the line-for-line port worked this cleanly: the dispatch prompt for the JS implementer was structurally explicit. Same coefficient names, same conditional branch order, same intermediate variable order. The implementer didn’t receive “here’s the Rothfusz spec, implement it” — they received “here’s the Python function, produce a JS function with this shape.” Functional equivalence specifications are harder to mess up than spec-derived reimplementations because the implementation is already partially specified by the thing being translated.
What the drift gate doesn’t catch
The gate has three real gaps, and I want to name them.
A wrong formula that both implementations correctly translate. This is the
Phase 1 advisor case exactly. If I had shipped the rejected 0.0345 * S / u^0.4
formula, both implementations would have faithfully produced a 6.68 °F RMSE against
the Liljegren reference — and the gate would have returned 24/24 PASS. The gate
can’t catch “the formula is wrong” because the gate’s reference values are generated
from the Python implementation, not from an independent external source. The gate
asserts parity, not correctness.
Numerical edge cases not represented in the 12 cases. The current set is dense between 27 and 50 °C, which covers the occupational heat-stress range well. It’s sparse below 27 °C (the simple-branch Rothfusz case at 26.11 °C is the only low-temperature case) and has no cases above 50 °C (Lytton at 49.6 °C is the ceiling). Adding a few sub-20 °C cases and a few synthetic near-zero-RH cases would tighten this. Not blocking for v1 given the occupational focus, but a v1.1 candidate.
Formula bugs that compound over aggregation. If a formula is systematically biased by 0.3 °F on every cell — inside the per-cell tolerance — a divergence map with 1140 cells would have a meaningful aggregate error while every individual assertion passes. The gate is per-cell, not aggregate. For an educational explainer this is acceptable; for anything used to actually compute exposure hours it’s not.
The skill stack
Phase 1 ran three implementer dispatches using superpowers:subagent-driven-development:
- Dispatch A: Python reference implementation,
_metrics.py, reference-case generation, and the tuning audit. The tuning pass — running four candidate formulas against five Liljegren cases — was what produced thewbgt-tuning.mddocument and the0.0125 * S / u^0.3formula. This dispatch came after the advisor catch; the formula was already corrected in the plan. - Dispatch B: JS port of
src/metrics.jsusingsuperpowers:test-driven-development, red→green againstreference-cases.json. The implementer got the reference file and the Python implementation; they were asked to produce JS that matched line-for-line. This is the dispatch that produced the 0.009 °F max delta. - Dispatch C: Drift script (
scripts/05_drift_check.py) and the GitHub Actions workflow (drift-check.yml). Three files, ~145 lines total.
Approximate token use per DEVREL.md: Dispatch A ~50k, Dispatch B ~36k, Dispatch C ~37k, plus Haiku spec/quality reviewers (~70k + ~72k + ~71k). Total Phase 1: ~340k tokens. That’s the cost of the rework the advisor prevented — one pre-implementation review call vs a full re-implementation of the Python formula, the JS port, the tuning audit, and the drift gate, all built on a wrong coefficient.
The advisor itself costs one call. It produces plain text. There’s no tool use, no file creation, no CI run — just a model with full context reviewing what’s about to be built. At 340k total for the phase, the advisor call is essentially rounding error. The question is whether you remember to call it for numerical kernels.
What I’d do differently
Wire the advisor as a standard checkpoint for any formula or numerical kernel,
not a deliberate manual call. On this build I caught the pattern and called it.
On a faster build under a deadline I might not have. The commit 9ccb9e7 message
records the correction; the decision to call the advisor before that commit was
an operator judgment call. A hook or checklist that asks “does this plan contain
a regression coefficient?” and surfaces the advisor recommendation would make the
behavior less dependent on deliberate choice.
Add low-temperature and low-RH edge cases to reference-cases.json. The
Rothfusz polynomial has documented edge behavior at the low-RH correction boundary
(below 13% RH, 80-112 °F). The current set has one case near that boundary
(Phoenix at 18% RH) but none below 13%. The Stull wet-bulb approximation also
degrades outside its stated validity window (5%-99% RH). Both boundaries should
have explicit test cases.
Publish _metrics.py as a standalone PyPI package. The file is 74 lines,
no external dependencies, pure Python. A reader who wants to verify the lab’s
numbers against their own data currently has to clone the repo and figure out
the project structure. A pip install heat-metrics-ref with a documented function
interface would lower that bar to one line. Not load-bearing for the educational
site, but consistent with the underlying goal of formula transparency.
What it bought
The lab shipped with a drift gate holding JS and Python within 0.009 °F across 24 assertions. It shipped with a globe-temperature formula that produces 1.37 °F RMSE against five published Liljegren reference cases, rather than 6.68 °F. The five-chapter scrollytelling narrative — 1140-cell divergence maps, five site scenarios, NIOSH work-rest table, live NWS integration — is built on formulas whose correctness has an audit trail.
 Plate 0 / hero. The three numbers displayed here — air temperature, heat index, WBGT — are computed by
Plate 0 / hero. The three numbers displayed here — air temperature, heat index, WBGT — are computed by src/metrics.js, which the drift gate holds within 0.009 °F of scripts/_metrics.py across 12 reference cases. The globe-temperature coefficient behind the WBGT number is tuned against five published Liljegren reference cases, with the rejected formula and its 6.68 °F RMSE documented at notes/wbgt-tuning.md for any reader who wants to follow the trail.
On the Google side (heat-protein-lab), formula work was structurally different — lookup values from verified scientific databases, not fitted polynomial regressions against occupational safety thresholds. The advisor catch is not a general indictment of unreviewed math; it’s specific to this category of formula: numerical fits used as proxies for regulatory decision thresholds. For that category, pre-implementation review is the right answer.
The full comparison post covers both builds across cost, toolchain, and quality outcomes. Phase 1 of heat-metrics-lab was the most expensive in rework prevented relative to cost incurred. 340k tokens, two correctness properties verified end-to-end, zero formula bugs shipped.